The report needed data gathered daily. The pipeline needed therapy.
Created on: 2026.06.12
AI Notice
AI was not used to write this article. This is entirely on me.
However, I did use AI to fix typos and incorrect grammar because I suck at that.
Model: gpt-5.5 Tool: codex
Over the last few months, I have been taking part in a STX Next powered Data Engineering Bootcamp. The main idea was simple on paper: build a data pipeline using AWS and dbt. In practice, it quickly became a useful reminder that data engineering is not just about moving files from one place to another. It is a chain of decisions about data shape, storage format, orchestration, schema discovery, transformations, and all the tiny assumptions that can quietly turn into a nightmare.
This post is my attempt to put that process in order. I want to walk through what I built, where AWS helped, where it made things more complicated, how dbt changed the way I thought about transformations, and what I learned while connecting all those pieces into something that could be explained, rerun, debugged, and finally improved.
Do not treat this article as a guide or a perfect reference architecture. It is more of a "lessons learned" post from someone starting his data engineering path from the perspective of a backend engineer.
It is worth mentioning that while I did a lot of the learning by breaking things myself, the actual guidance came from my mentor, Maks.
PS. When your mentor asks, "Maybe let's see what will happen if…" - run.
The initial idea, built with duct tape and trytytki
I will be quite honest with you. I did not have much infrastructure experience on AWS when I started this project. I was more of a GCP person, and while both platforms offer similar building blocks, the mental models are different enough to make you second-guess almost every service choice.
So when I got the task to prepare an ELT or ETL pipeline (the choice was up to me), including ingestion, transformations, and a final report, I started looking for ways to connect all the dots. Or maybe all the boxes. Or maybe all the billable resources.
Anyway, the first draft looked something like this:
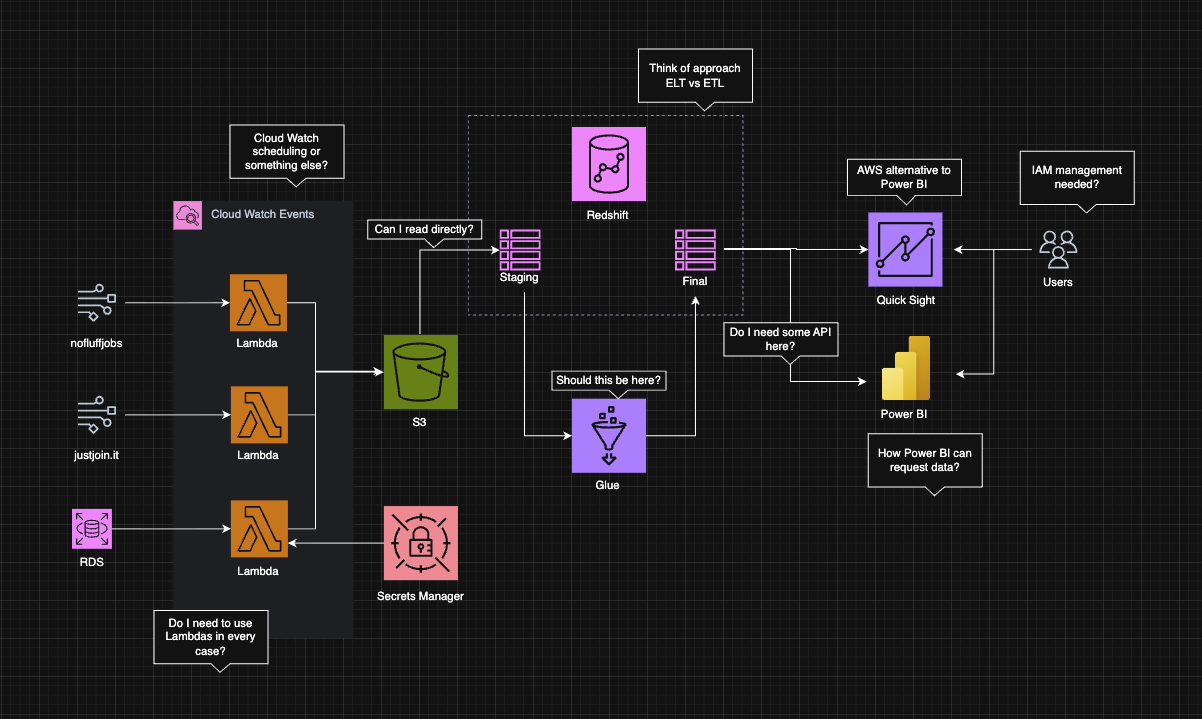
At this point, I had more questions than architecture.
- How do I schedule this thing?
- Is
Redshiftthe way to go? - ELT vs ETL?
- Where should raw data live?
- What should be responsible for schema discovery?
- How do these services even talk to each other?
- So, how do I
Gluethis together? (pun intended)
It was still overwhelming, but with help from my mentor, AI-assisted questioning, documentation, and blog posts… I started to pinpoint what did not work in that version and what connections had to be made.
After a while, I got to draft number two:
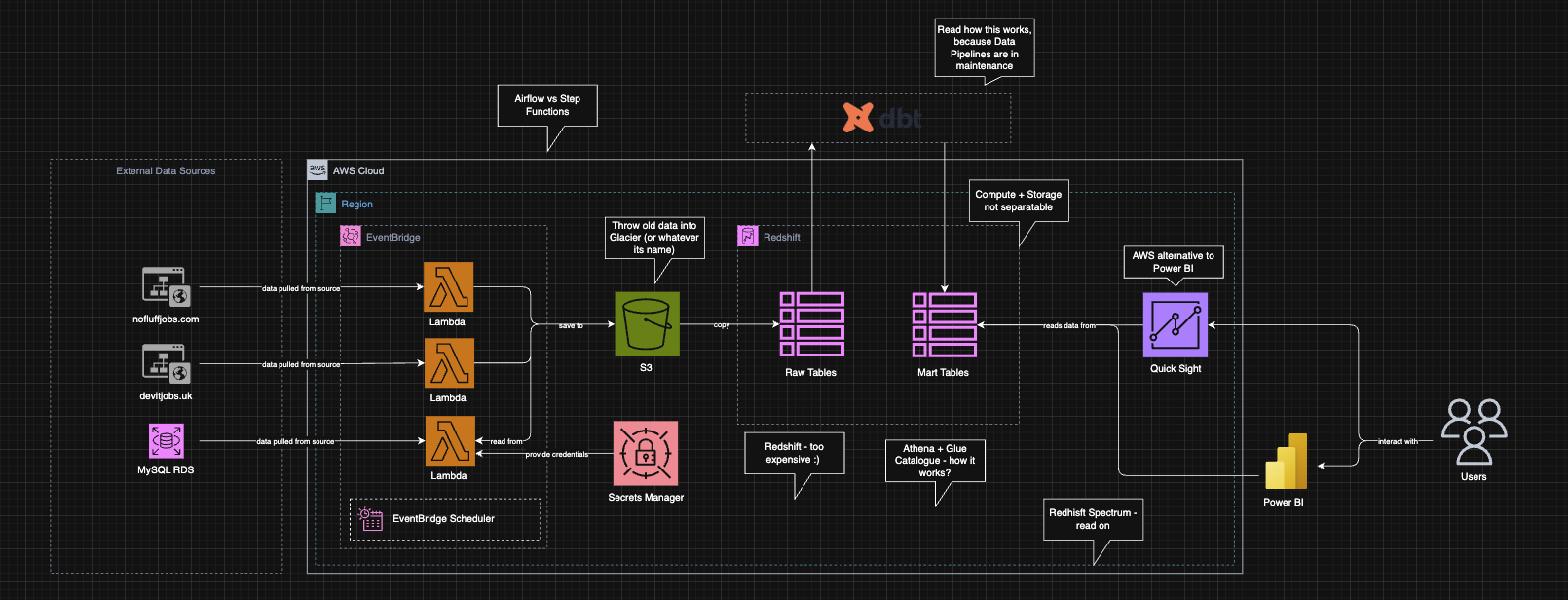
As you can see, even the graph was fancier this time. I marked boundaries more clearly, the DAG flow looked less like spaghetti, and dbt appeared somewhere along the way. That already felt more like a data platform and less like "Lambda calls a thing, probably".
Still, the second version had issues:
- How would AWS know what to run in each step, and in what order?
- Should orchestration live in code, in a scheduler, or in a state machine?
- I still did not really know how
dbtworked. I had mostly heard that it was good, which is not exactly an implementation strategy. - I was planning to use Redshift, which felt a bit like shooting a fly with a cannon.
- An idea about Greek gods appeared. Athena? Never heard of her…
So finally, after a lot of trial and error, I arrived at something I was happy with.
Behold the solution.
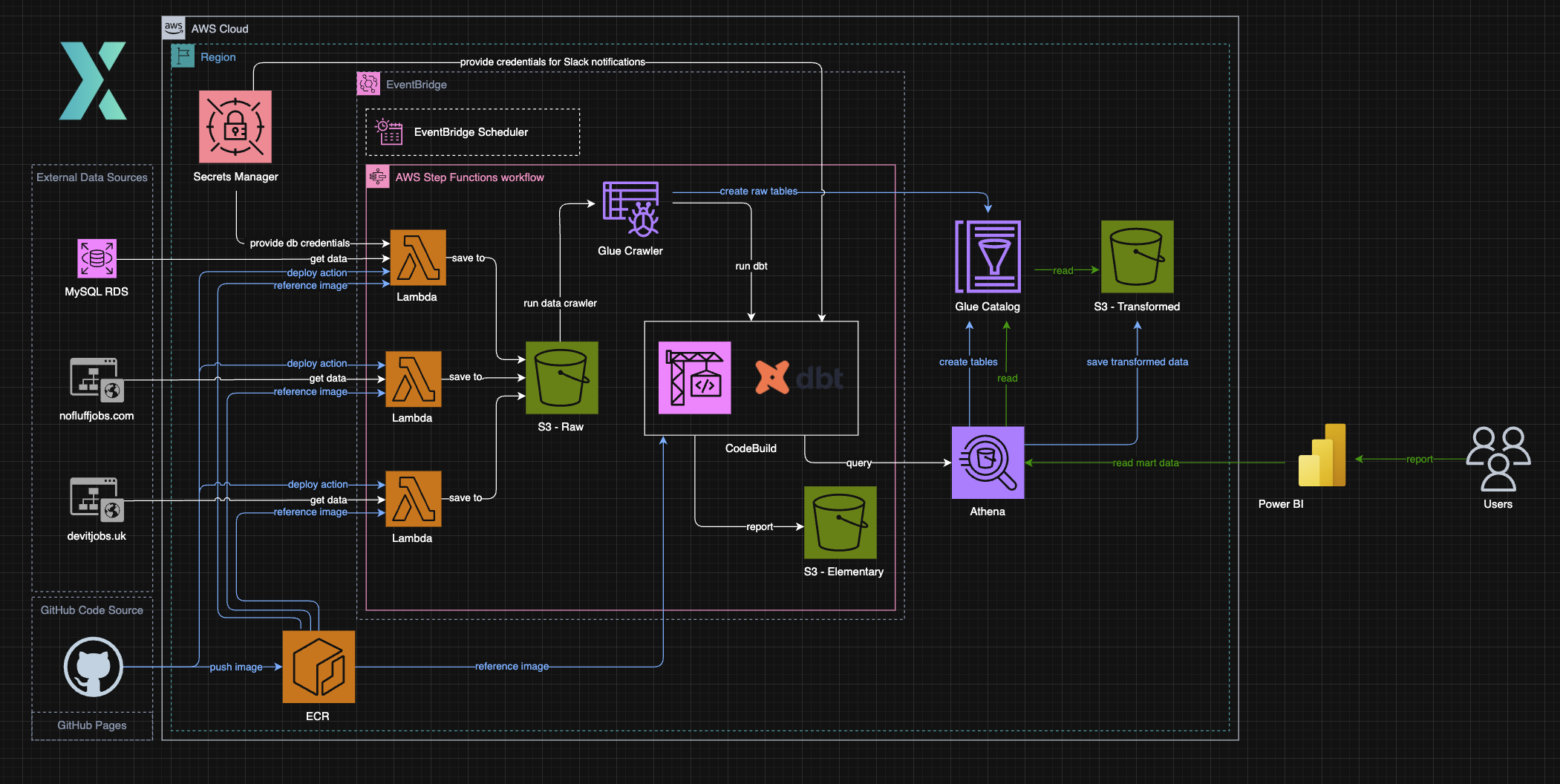
The final architecture consists of multiple AWS services hosted in a single region. It supports the full ELT process: gather information from source systems, land it in storage, catalog it, transform it, and make the final data available for analysis.
The shape is lakehouse-ish, but still small enough to understand without asking your favourite AI agent. Lambda handles extraction, S3 stores raw and transformed data, Glue gives Athena something table-shaped to query, Step Functions keeps the flow explicit, and dbt runs as a containerized transformation layer rather than a mysterious SQL folder on someone's laptop.
The following services were used:
- Lambda: Runs Python extractors and gathers data from the required sources.
- S3: Stores raw data, transformed data, and Elementary reports.
- Secrets Manager: Provides secret values for the database and Slack notifications.
- EventBridge and Scheduler: Trigger the pipeline on a schedule.
- Step Functions: Defines the step-by-step flow and makes failures visible.
- ECR: Stores prepared container images.
- CodeBuild: Runs dbt in a controlled environment.
- Glue Catalog and Crawlers: Discover schemas and expose S3 data as tables.
- Athena: Queries the cataloged data and gives dbt a serverless SQL engine.
How I built ELT and survived to tell the tale
ELT stands for Extract, Load, Transform, which is a fancy way of saying: grab the data first, store it somewhere durable, and only then start making it useful. In this project, that meant Lambda pulled data from the source systems, S3 became the landing zone for raw files, Glue and Athena made that data queryable, and dbt handled the part where chaos slowly became models, tables, and something a human could put in a report. Compared with classic ETL, the important shift is that transformation happens after loading, inside the analytics layer, where SQL, lineage, and repeatable models can do their work instead of hiding business logic inside ingestion scripts.
One could argue that I actually built EtLT, because I still did some light transformation during extraction. Again, those changes appeared because my mentor decided to ask one of those "What if?" questions that later gave me a headache.
A bit on the technical side
Before diving into the ELT process itself, let's quickly map the technical stack. I used the following technologies:
- All AWS infrastructure resources were described in
TerraformandTerragrunt. - Lambda functions were written in
Pythonwith a few helpful packages:dltgathered database and API responses.playwrightscraped site data.polarsbuilt dataframes.
dbthandled data transformations.- GitHub Actions for the following automations:
- Images were built and deployed to
ECR. - The solution was linted to maintain code formatting.
dbtdocs were published to GitHub Pages.
- Images were built and deployed to
The repository followed the Conventional Commits approach.
The full solution is available in my lukzmu/stx-de-bootcamp repository.
A quick step over the Step Functions
Building a data pipeline is basically following a simple DAG (a fancy acronym for Directed Acyclic Graph - a flow that only moves in one direction). You can notice this when looking at my Step Functions configuration.
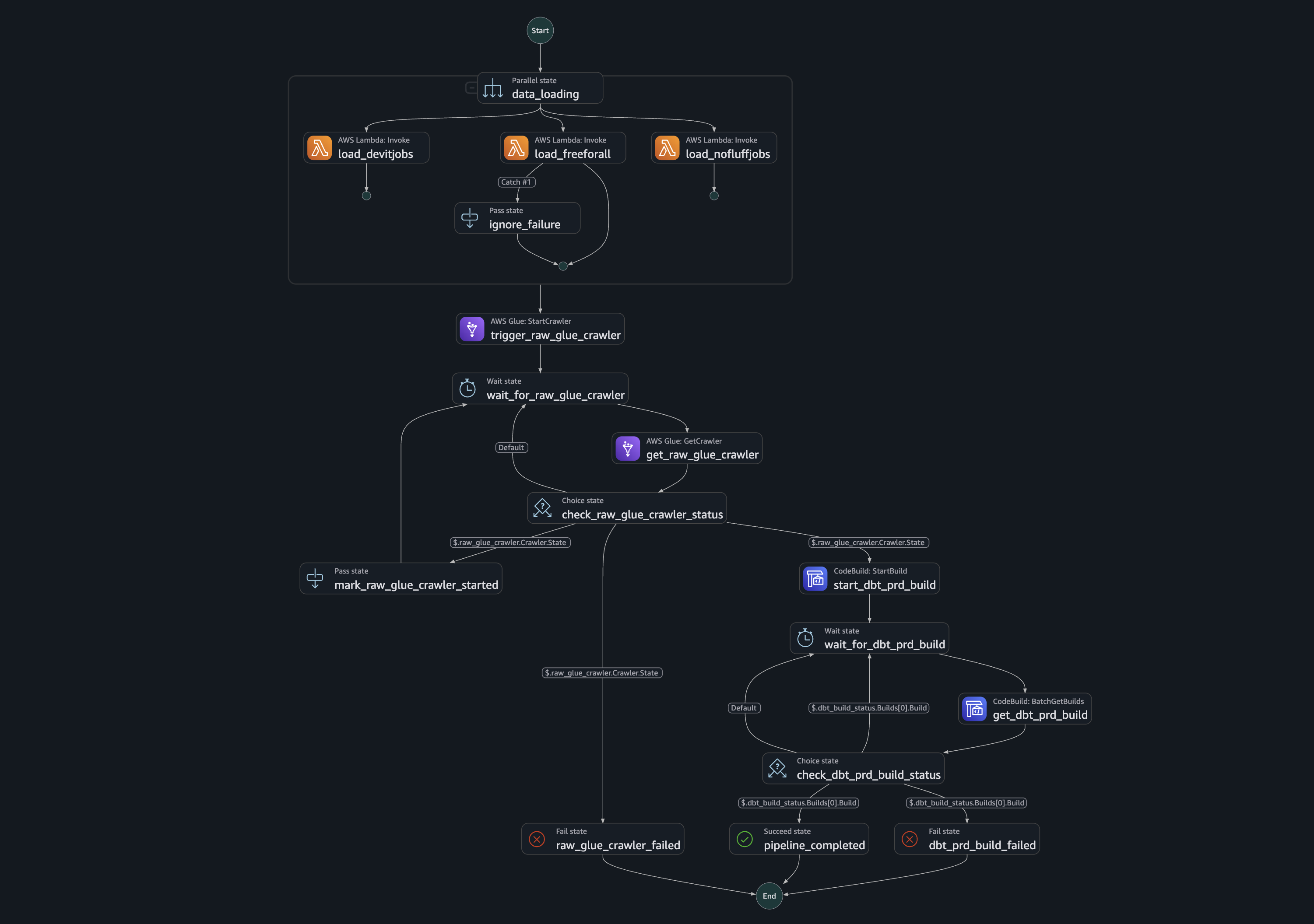
While this graph looks complicated at first, you can quickly notice that it just follows a couple of steps, with occasional loops that check whether a step has already finished. Here are the steps that are performed:
- Gather data from sources in parallel:
- One
Lambdaloads data from devitjobs.uk. - One
Lambdaloads data from nofluffjobs.pl. - One
Lambdaloads data from the currency database, and this job can fail.
- One
- Trigger
Glue Crawlerto go through gathered data inS3. - Trigger
CodeBuildto rundbttransformations andElementary.
This is scheduled to run twice a day.
The Infrastructure
The infrastructure part was less glamorous than the pipeline diagram, but probably the most important one. I described AWS resources with Terraform and Terragrunt so the project could be recreated without clicking through console tabs and hoping I remembered every setting. That mattered because the pipeline had many small dependencies: IAM permissions, bucket paths, Lambda configuration, container images, Step Functions states, crawlers, schedules, secrets, and the glue between them. When one of those is configured by hand, it becomes very easy to forget why it exists or make the next run behave differently.
Treating infrastructure as code also forced me to understand the edges between services. IAM roles stopped being abstract "permissions magic" and became part of the design. S3 prefixes had to match crawler expectations, Step Functions had to know what to invoke, and CodeBuild needed enough context to run dbt consistently. It was slower at the beginning, but it made the final solution clean and explainable.
Deployment plumbing
The first infrastructure problems were not very cinematic. GitHub workflows did not yet have all the pieces needed to deploy Lambdas properly: role ARN secrets were missing, the ECR registry environment was not wired, Lambda update commands were incomplete, and deployment IAM policies lacked some required actions. The fix was mostly disciplined plumbing: add the missing workflow environment, update the Lambda deployment steps, and grant only the IAM actions the pipeline actually needed.
The same kind of issue appeared in the dbt image path. Publishing a new image did not automatically point CodeBuild at the new SHA tag, so the workflow had to update the CodeBuild project directly after publishing. Even the Docker build itself had a surprise in it: mmh3 needed native build tooling under Python 3.13, so the builder stage needed compiler dependencies instead of assuming every package would arrive as a wheel.
Production orchestration
Production orchestration also exposed several small AWS integration gaps. Step Functions expected the wrong CodeBuild response shape, CodeBuild needed more permissions, Athena needed access to its output bucket, and Elementary needed Glue table-version permissions. None of these were conceptually difficult, but each one proved that production pipelines fail at the boundaries between services as often as they fail inside the code.
The crawler gate was the most subtle orchestration issue. Glue could report stale READY and SUCCEEDED states before the current crawl had actually run, which meant dbt could start against an old catalog. The safer version tracked whether the current execution had observed the crawler running before allowing the next step to begin.
The important part was not the wait loop itself, but this small state flag:
{
And = [
{
Variable = "$.raw_glue_crawler.Crawler.State"
StringEquals = "READY"
},
{
Variable = "$.raw_glue_crawler_started"
BooleanEquals = true
},
{
Variable = "$.raw_glue_crawler.Crawler.LastCrawl.Status"
StringEquals = "SUCCEEDED"
}
]
Next = "start_dbt_prd_build"
}
mark_raw_glue_crawler_started = {
Type = "Pass"
Result = true
ResultPath = "$.raw_glue_crawler_started"
Next = "wait_for_raw_glue_crawler"
}
The Extraction
The extraction part was where the pipeline had to touch the messy outside world. Lambda was a good fit here because each extractor could stay small, focused, and disposable: call the source, shape the response just enough to make it serializable, and push the result forward. The important lesson was not to make extraction too clever. At this stage, the job is to capture data as faithfully as possible, keep failures visible, and avoid burying business logic inside a script that future-me would have no clue about.
Stable Lambda output
Early extraction fixes were mostly about making Lambda output predictable. S3 paths drifted, bucket names were wrong in places, uploaded filenames were inconsistent, partition fields were missing, and temp paths were not safe enough for repeated Lambda runs. I handled this by standardizing upload paths, adding date partitions, cleaning up temp-file handling, and making the Lambda deployment configuration match the runtime behavior.
Source changes
The Dev IT Jobs source changed underneath the scraper. Optional and day-rate salary cards appeared, some fields could no longer be treated as guaranteed, and the page behavior changed enough that the scraper timed out. The final extractor made optional fields non-blocking, found the real scroll container, used bounded scrolling, and converted day rates into annual salary ranges so the downstream salary model had a consistent starting point.
The bigger lesson, which I described separately in Scraping dynamic pages with Python, Playwright and AWS Lambda, was that this was not a simple HTML parsing problem. The page behaved like a small frontend: job cards appeared in chunks, the DOM changed while the scraper was running, and scrolling the whole page was not enough because the actual lazy-loading happened inside .joblist-container. That made the scraper more about controlling browser behavior than parsing text. I needed headless Chromium flags that worked inside Lambda, stateful extraction with already-handled job IDs, and bounded scrolling so a site change would fail visibly instead of timing out forever.
A small example of that adaptation was converting day-rate cards into the annual range shape already expected by the rest of the pipeline:
_WORKING_DAYS_PER_YEAR = 260
_DAY_RATE_PATTERN = re.compile(
r"(?:£\s*)?(?P<from>\d[\d,]*)\s*-\s*(?P<to>\d[\d,]*)\s*GBP\s*/\s*day",
re.I,
)
def _annual_salary_from_day_rate(day_rate: str | None) -> str | None:
if not day_rate:
return None
match = _DAY_RATE_PATTERN.search(day_rate)
if not match:
return None
salary_from = int(match.group("from").replace(",", "")) * _WORKING_DAYS_PER_YEAR
salary_to = int(match.group("to").replace(",", "")) * _WORKING_DAYS_PER_YEAR
return f"{_format_gbp_salary(salary_from)} - {_format_gbp_salary(salary_to)}"
There was also an ingestion decision that I intentionally did not fix at this layer. Some Dev IT Jobs rows had no technology badges, and those empty values later polluted the mart path after split/explode logic. Instead of inventing missing technologies during extraction, I left ingestion faithful to the source and handled the blank badge strings in dbt.
Undocumented API shape
No Fluff Jobs was a different kind of extraction problem. It was not a browser-scraping task, but the search request shape was not documented in a way I could just copy into dlt. I ended up looking at necsord/go-nofluffjobs to understand that search used a POST request with query parameters for currency, salary period, and region, plus a JSON body for the actual search criteria.
Once that shape was clear, dlt could handle the pagination and Parquet data:
source = rest_api_source(
{
"client": {
"base_url": "https://nofluffjobs.com/api/",
"headers": {
"Content-Type": "application/json",
"Accept": "application/json",
},
"paginator": {
"type": "offset",
"limit": 50,
"offset": 0,
"total_path": "totalCount",
},
},
"resources": [
{
"name": "posting",
"endpoint": {
"path": "search/posting",
"method": "POST",
"data_selector": "postings",
"params": {
"salaryCurrency": "PLN",
"salaryPeriod": "hour",
"region": "pl",
},
"json": {
"rawSearch": "data engineering",
},
},
},
],
},
)
The Loading
Loading was mostly about giving the data a stable, predictable home. S3 became the raw landing zone and the place where transformed results could live later, which sounds simple until you start caring about prefixes, file names, reruns, overwrites, and whether your bucket layout will make sense at 2 AM. This is also where Glue Crawlers entered the story: once the files were in S3, the catalog had to understand them well enough for Athena to query them. In other words, S3 stored the bytes, Glue explained what the bytes meant, and Athena pretended it had always been a database.
Raw schema drift
The hardest loading problems lived at the S3, Glue, and Athena boundary. Raw Parquet physical types and Glue table types kept disagreeing, especially around Free For All currency rates and No Fluff Jobs posting fields. The practical fix was to make raw Lambda outputs more string-compatible, rerun crawlers when the catalog needed to catch up, and let dbt perform safer casts later instead of pretending the raw layer was already clean.
Historical repair
No Fluff Jobs had an extra problem: even after the current code was partly fixed, old S3 objects still contained bad Parquet schemas and caused HIVE_BAD_DATA in Athena. I handled this with a data fix script, dry-ran the repair first, backed up the originals, and repaired five bad April files instead of deleting history or hoping Athena would ignore them.
The Transformation
Transformation was the point where dbt started to make sense. Instead of hiding cleanup logic in extractors or manually poking SQL into Athena, I could split the work into models: staging, intermediate, and mart tables that were easier to reason about. Bad input data did not magically become good, but dbt made the failure modes more civilized: SQL lived in version control, dependencies were explicit, lineage was visible, and every model had a place in the graph.
Running it through CodeBuild also made the process feel less like "works on my machine" and more like an actual pipeline step.
Model layers and contracts
The first dbt shape was too messy. Staging names collided, chains between models became fragmented, and disabled models were awkwardly configured. I moved the project toward clearer staging, intermediate, and mart layers, then later consolidated provider staging chains while keeping disabled source-aligned models where they still helped explain the raw contract.
Types, salary, and currency
Because the raw layer leaned string-heavy, the transformation layer had to take typing seriously. Salaries, booleans, timestamps, arrays, and numerics were cast in staging and intermediate models with try_cast and reusable macros. This made bad input survivable without silently turning every downstream query into a guessing game.
Salary normalization was the most involved example. Dev IT Jobs had GBP annual strings and day rates, No Fluff Jobs had several salary modes and currencies, and the final output needed monthly PLN, EUR, and USD values. I handled this with salary parsing, hourly-to-monthly and annual-to-monthly macros, FX-rate joins by date, and midpoint calculations.
The currency join needed one more correction. I initially questioned whether _dlt_* metadata should drive conversion, but the right temporal anchor was created_at. The final version derived rate dates from created_at, selected the latest valid rates, and removed unnecessary _dlt_* load metadata from the staging contract. The row identifier still appears in the join logic, but only as a grain key, not as the source of time.
In dbt, that became an as-of join: only rates from the posting date or earlier were eligible, and then the latest matching rate won.
ranked_rates as (
select
postings._dlt_id,
currency_rates.base,
currency_rates.target,
currency_rates.rate,
currency_rates._created_at,
row_number() over (
partition by postings._dlt_id, currency_rates.base, currency_rates.target
order by currency_rates._rate_date desc, currency_rates._created_at desc
) as rate_order
from postings
inner join currency_rates
on currency_rates._rate_date <= postings._load_date
),
latest_rates as (
select *
from ranked_rates
where rate_order = 1
)
Grain, deduplication, and tests
Grain took several rounds to clarify. Job postings, No Fluff child rows, and technology rows could duplicate in different ways, so I added row-number dedup models, uniqueness tests, and targeted fixes for the No Fluff duplicate grain. The technology mart also needed one explicit cleanup: blank badge strings were filtered before creating the by-technology model, which fixed the missing Dev IT Jobs technology issue without changing ingestion.
Tests were useful because they found real problems, not just theoretical ones. They exposed blank technologies, duplicate (posting_key, technology_name) pairs, and an over-strict salary bounds check. The fixes were correspondingly different: remove blank technology rows, identify the narrow No Fluff duplicate case, and remove or relax the redundant metric-bounds test.
Tooling, docs, and Elementary
The dbt toolchain had its own share of tiny paper cuts. Renamed data_tests, package deprecations, lockfile changes, and mise or uv commands were not glamorous, but they made the project reproducible. The annoying part was that some checks wanted to talk to Athena even when I only needed a local sanity check. I ended up separating validation into two buckets: quick offline checks with --no-populate-cache, --empty-catalog, and profile-free parsing, and slower live checks for cases where catalog metadata actually mattered.
dbt-checkpoint became another boundary problem. Because the dbt project lived below the repository root, hooks initially looked in the wrong place, and catalog-backed checks ran before docs existed. A dedicated .dbt-checkpoint.yaml, explicit hook arguments, generated docs, and a rebuilt dev table turned those checks from noisy blockers into useful guards for contracts like boolean column naming.
Elementary was the most "it works, but only if you wire the wonky parts" tool in the project. dbt build maintained the package models, but it did not produce the browsable HTML report, so the pipeline needed edr report plus a small upload script for index.html. The profile also had to exist inside the production image, not just on my laptop, and Slack alerts needed Secrets Manager values plus a preflight channel check before edr monitor could run without tripping over its first message.
Summary
The biggest lesson from this project is that data engineering is mostly about making hidden assumptions explicit. Most problems were not caused by one bad SQL file. They were boundary issues between raw scraped data, Parquet and Glue schemas, Athena behavior, dbt contracts, and AWS runtime wiring. The fix was to harden those boundaries one by one: normalize raw writes, repair historical data, make dbt casts and tests explicit, validate without live AWS dependencies where possible, and add narrow runtime permissions or scripts only where production actually needed them.
Here are the lessons I am taking from it:
- Raw data should be boring.
If raw files have inconsistent paths, missing partitions, surprising parquet types, or "sometimes boolean, sometimes string" columns, every later layer pays the price. - Schema drift is not a theory.
It happens when APIs change, websites change, crawlers infer something new, or historical files keep an old shape. - Do not put too much intelligence in extraction.
Extraction should collect data and make failures visible. The moment business logic starts hiding inside a scraper, you lose a clear picture of the data. - Undocumented APIs are still APIs, just more annoying.
No Fluff Jobs required a bit of reverse engineering beforedltcould do its job. Once the realPOSTshape was known, the problem was solvable. - dbt works best when layers have a job.
Staging, intermediate, and mart models are not just naming ceremony. They help decide where transformations should actually live. - Use tests. Always.
The useful tests were not created just to create tests. They caught blank technologies, duplicate grains, broken contracts, and assumptions that looked fine. - Orchestration needs state, not vibes.
Waiting for a crawler to beREADYwas not enough, because it could be ready from a previous run. I needed to know whether it had actually finished in the current execution. - Permissions should be narrow, but complete.
Missing IAM actions are a chore until the workflow stops on them. The trick is to add the exact permissions the runtime needs, and no more. - Local validation should avoid the cloud until it cannot.
Profile-free checks, empty catalogs, and static docs generation kept feedback fast. Live validation was necessary, but only when production had to be validated.
AWS gives you a lot of bricks, dbt gives you a sane way to build the transformation wall, and the real work is figuring out which parts should stay simple before the architecture starts cosplaying as enterprise software. At some point, the goal is not to make the pipeline clever. The goal is to make it predictable enough that when something breaks, you know exactly which part to inspect first…
… but you know what? With all the problems I encountered, this was a very fun project to do. Especially because I learned much more than expected.
10/10 would fix errors at 2 AM again.